

Continuous and classified data in Context
“Classified (or discrete or categorical) data represent named groups of values, for example, high, medium and low hazard. Continuous data represent a continuously varying phenomenon such as depth.”
In this module, we will explore both classified and continuous data and their visualisation and application in QGIS.
You try:
Goal: Explore and map continuous and classified data
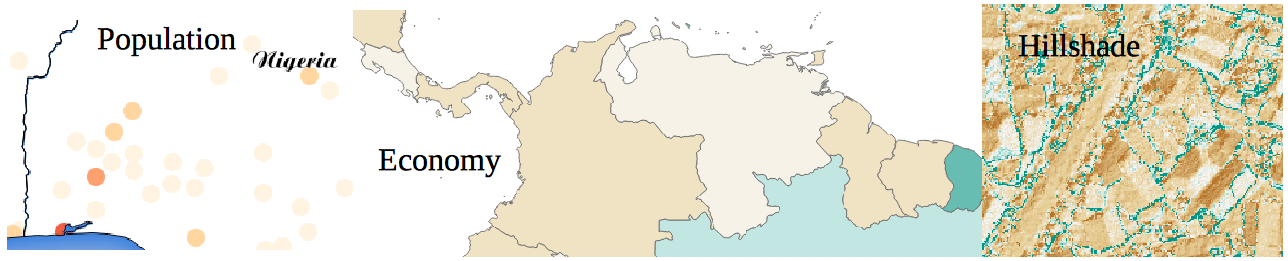
Load the Countries and Populated Places layers from Natural Earth.
- In the Populated Places layer, inspect the data in the "pop2015" field. Style the layer accordingly.
- In the Countries layer, inspect the 'economy' field. Style the layer accordingly.
- Load the tandale_hillshade.tif. Look at it carefully and explore the cell values. Try to style it differently.
- Challenge: try to turn some continuous data into classified data using tools available in QGIS (this must result in a new data set, not just a style).
Check your results
Do you get anything like the maps in the screenshots above?
What do the values in the hillshade layer represent?
| Name | Expectation |
|---|---|
Countries layer |
ne_10m_admin_0_countries in the classified-data/ne.sqlite database |
Populated places layer |
ne_10m_populated_places in classified-data/ne.sqlite |
tandale_hillshade.tif |
In classified-data/exercise-data |
More about
While many phenomena that we want to map or analyse exist as continuous data, grouping or classifying values works well when you wish to reduce data preparation complexity or deal with local variances in the interpretation of data. For example, a flood depth of 50cm may represent a high hazard zone in an area where people commonly have basements in their houses and a low hazard zone in areas where people commonly build their houses on raised platforms.

Check your knowledge:
-
If you take continuous data and classify it in a style, does that make the data classified:
- Yes
- No
-
Is a binary (0/1 or yes/no) field continuous:
- Yes
- No
-
Can a text field be continuous:
- Yes
- No

Further reading:
-
Continuous_and_discrete_variable : https://en.wikipedia.org/wiki/Continuous_and_discrete_variable
Download the sample data for the lesson.